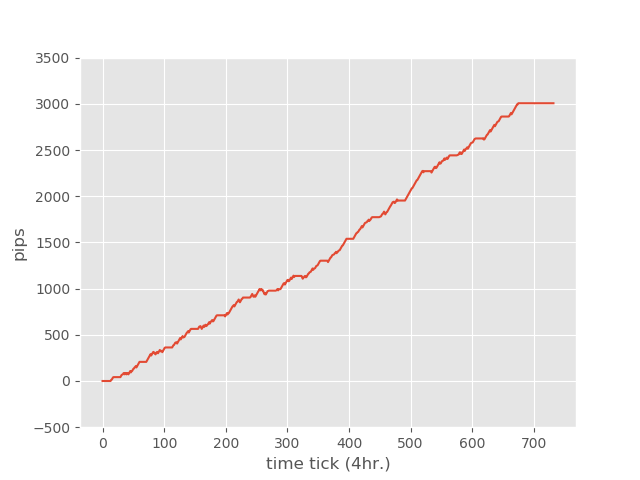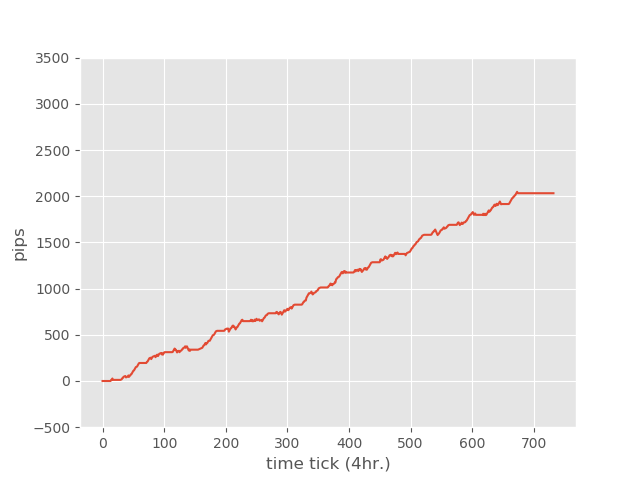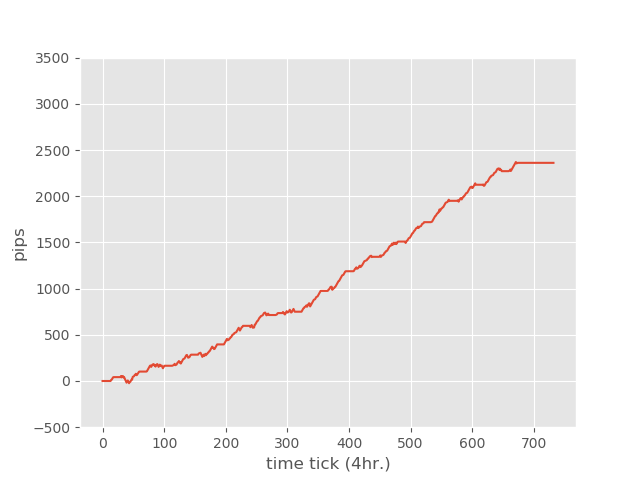
EURUSD - 4H
2018/08/01~2018/11/30
| Total Trades | Win Trades | Lose Trades |
| 866 | 715 | 151 |
| Net Profit | Profit Factor | Max Drawdown |
| 2361 | 2.32 | -3.30% |
Reinforcement Learning is cool.
There are still lots of things to learn.

Trained with Reinforcement Learning,
Developed and Tuned by Chun-Chieh Wang.
SURE-FIRE Hedging Strategy is used.
In recent years, FinTech has become a popular topic. One of the things is "Robo-Advisor", which allows investors to get advice on money management or investment at a low cost. However, most of the investors are not interested in the investing strategies that the robo-advisors executed, instead, they will just choose a robo-advisor according to the past investment performance provided by the industry. There is no way to confidently understand the actual investing strategy.
The goal of this project is to develop a foreign exchange investment strategy optimization platform.
The forex trading technique is simply...awesome. If you are able to look at a chart and identify when the market is trending, then you can make a bundle using the below technique. If we had to pick one single trading technique in the world, this would be the one! Make sure to use proper position sizing and money management with this one and you will encounter nothing but success!
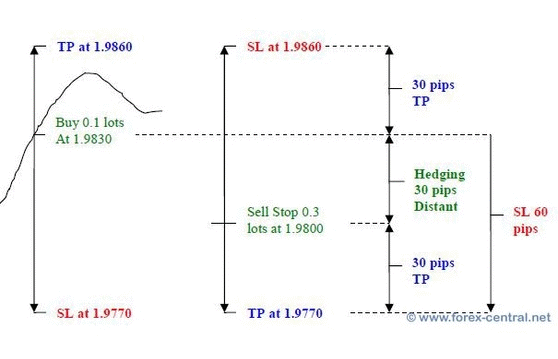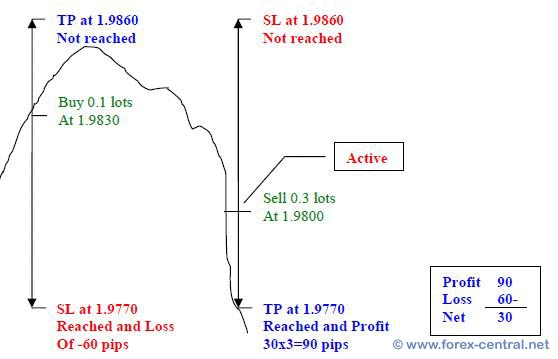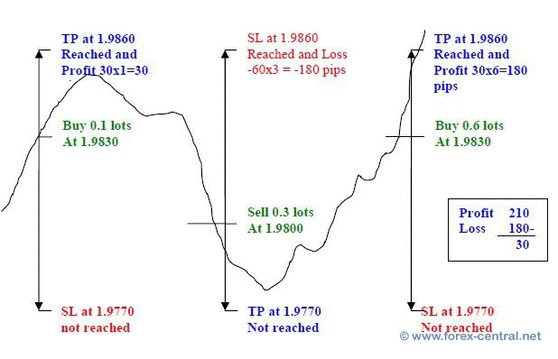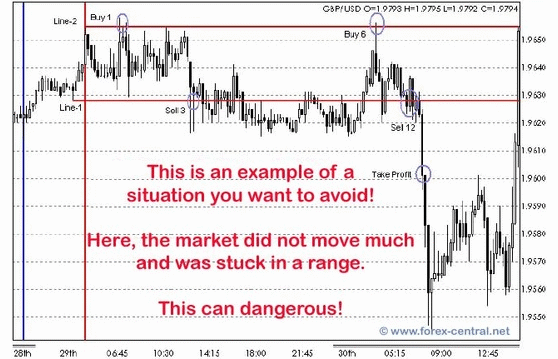
The basic Sure-Fire strategy is based on the sense of a trader. Hyperparameters such as the ratio of take-profit and stop-loss, usually depend on the traders' observation or experience.
Here are the results of setting 30 pips of take-profit and 60 pips of stop-loss:
| Total Trades | Win Trades | Lose Trades |
| 866 | 715 | 151 |
| Net Profit | Profit Factor | Max Drawdown |
| 2361 | 2.32 | -3.30% |
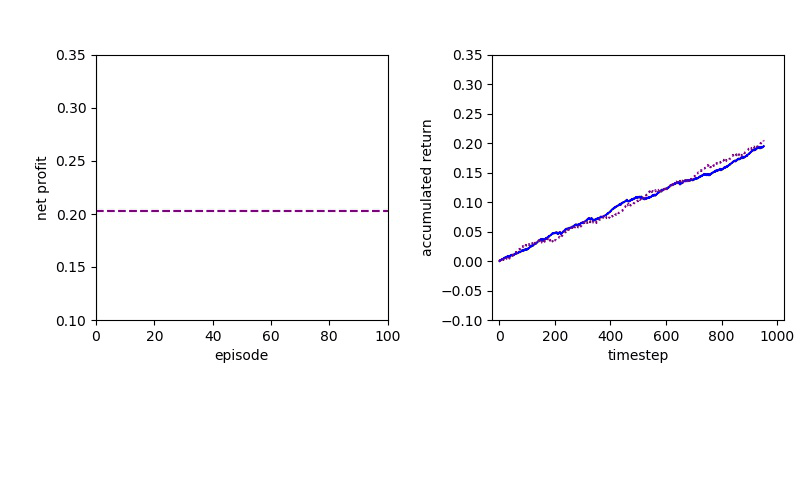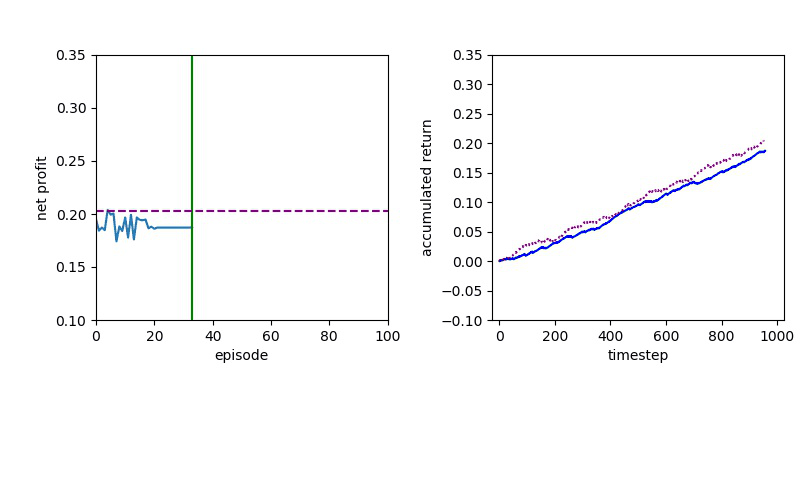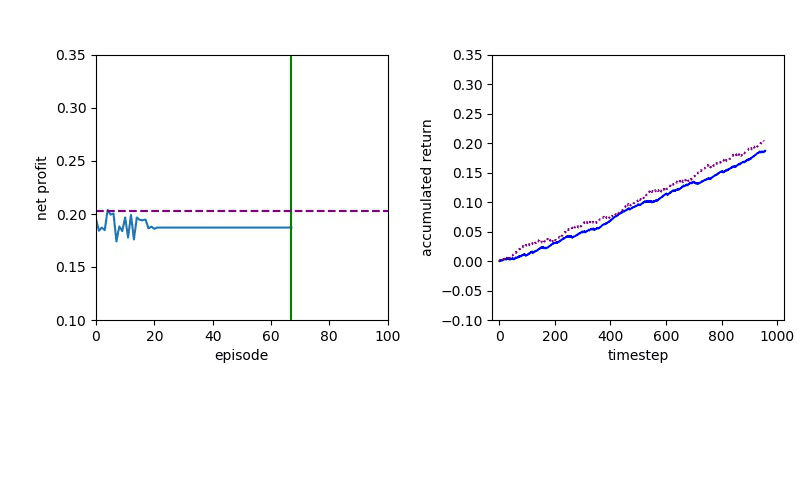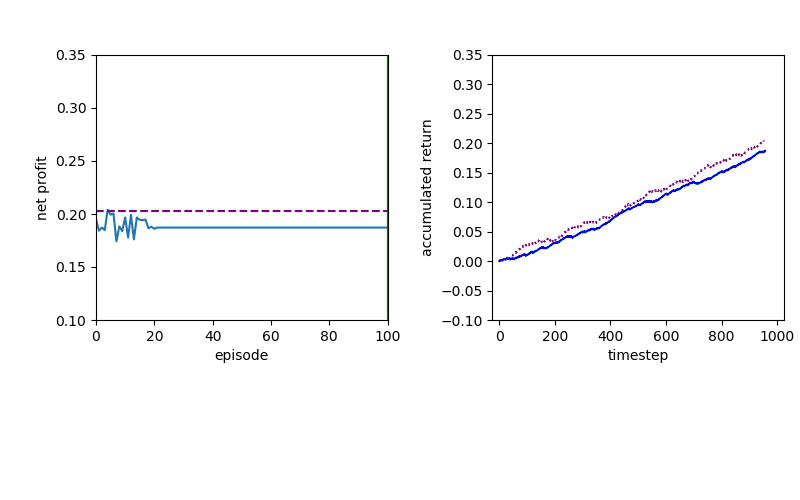
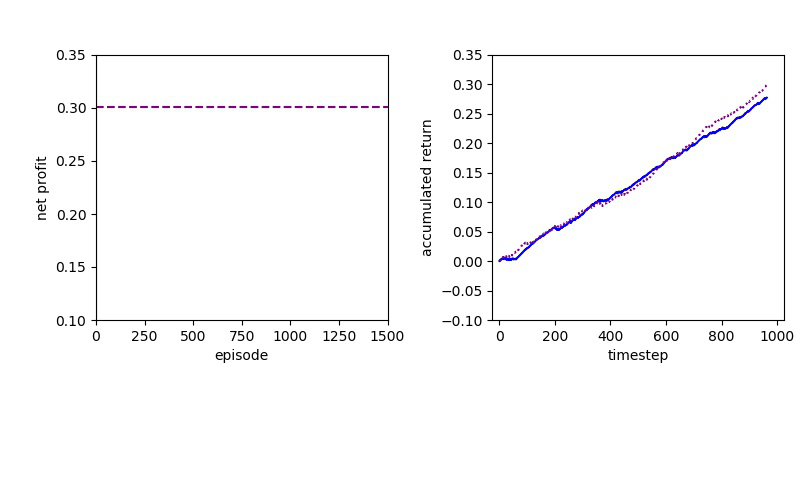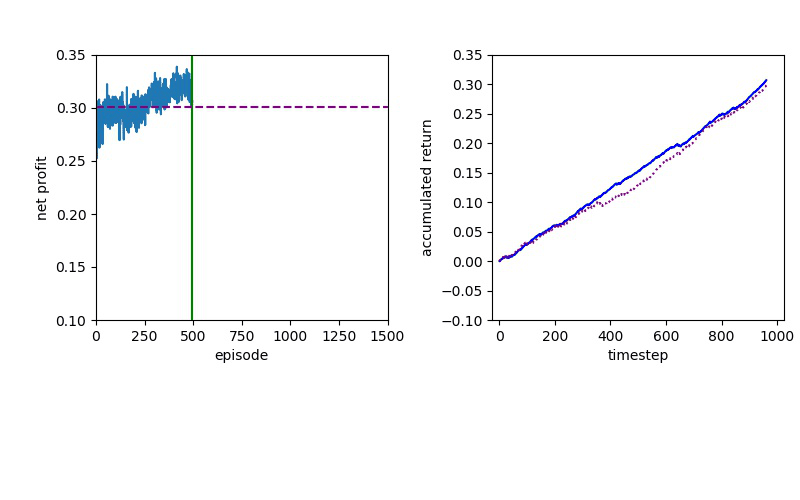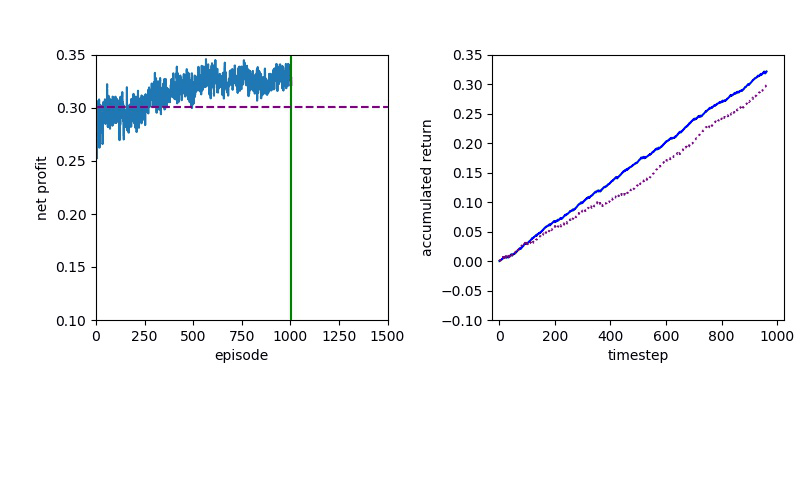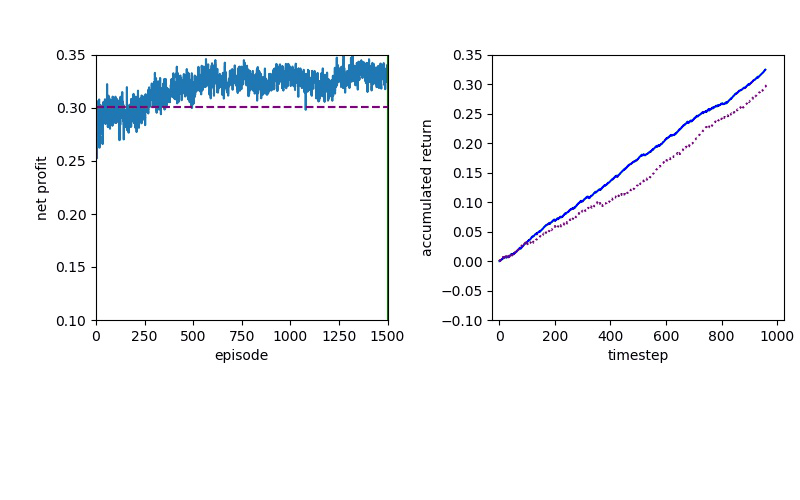
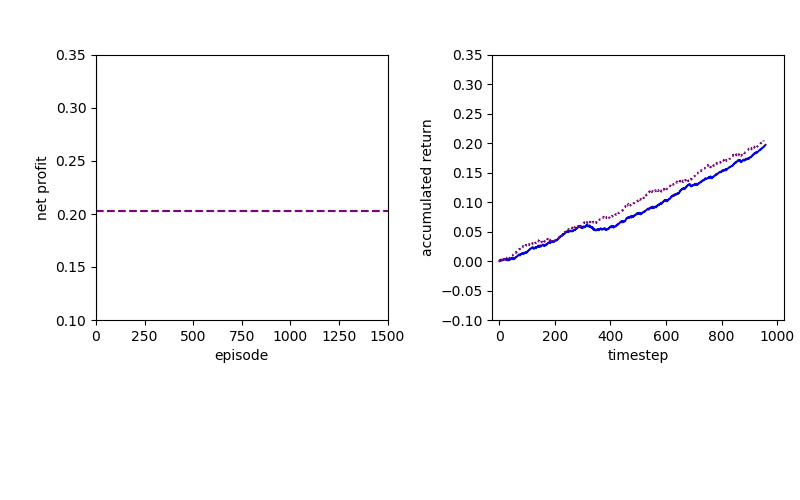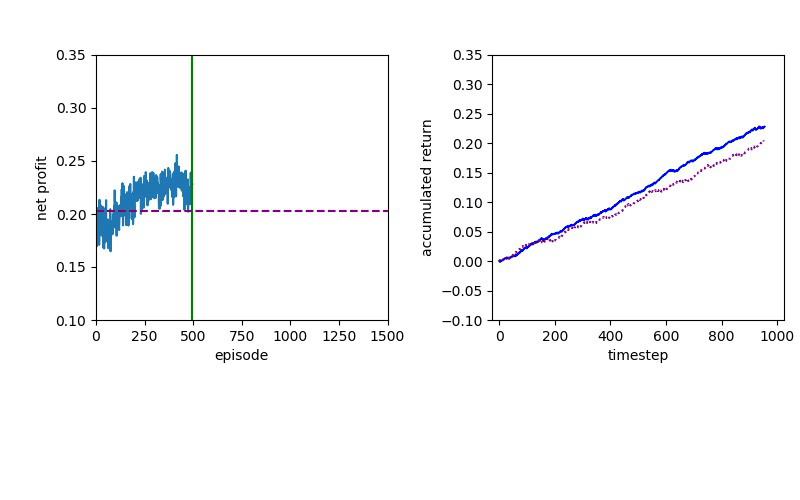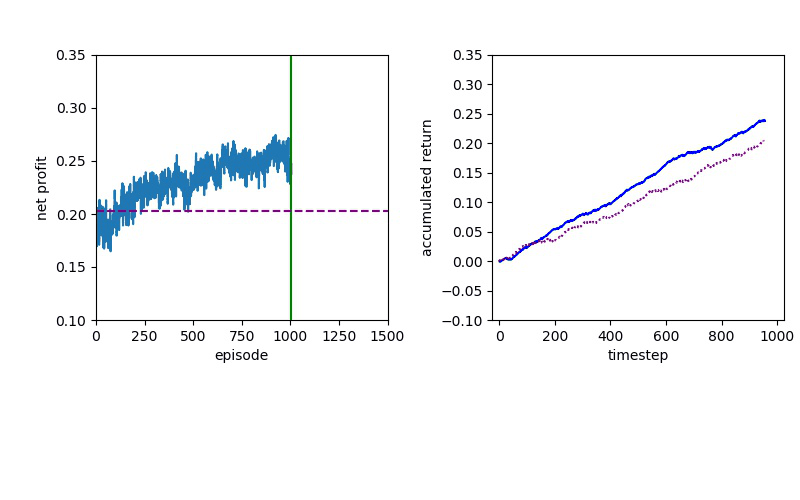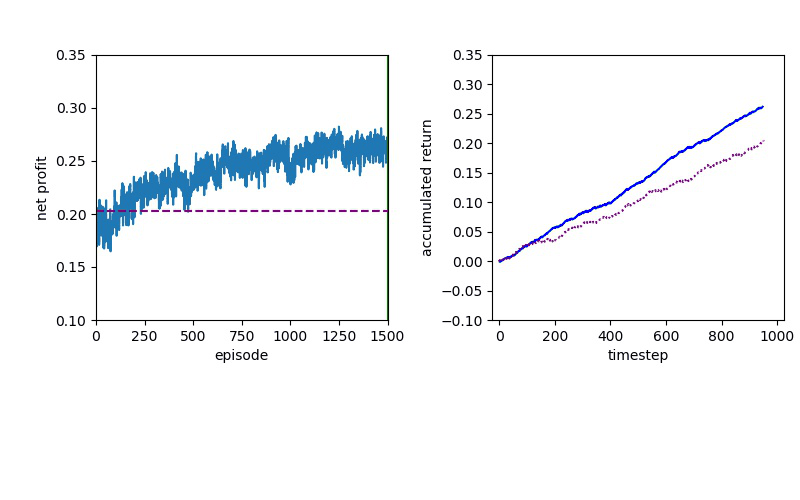
I've been looking for a best algorithm to complete my learning method, so I decided to try both Value-based and Policy-based methods.
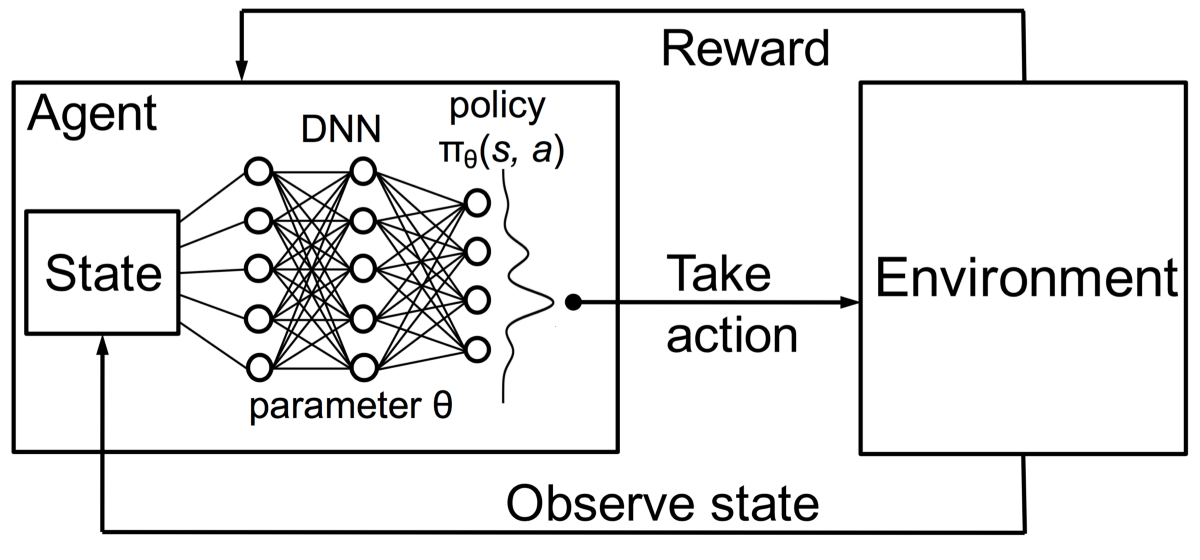
The Deep Q learning is about using deep learning techniques to represent the Q table that based on the Q-Learning algorithm.
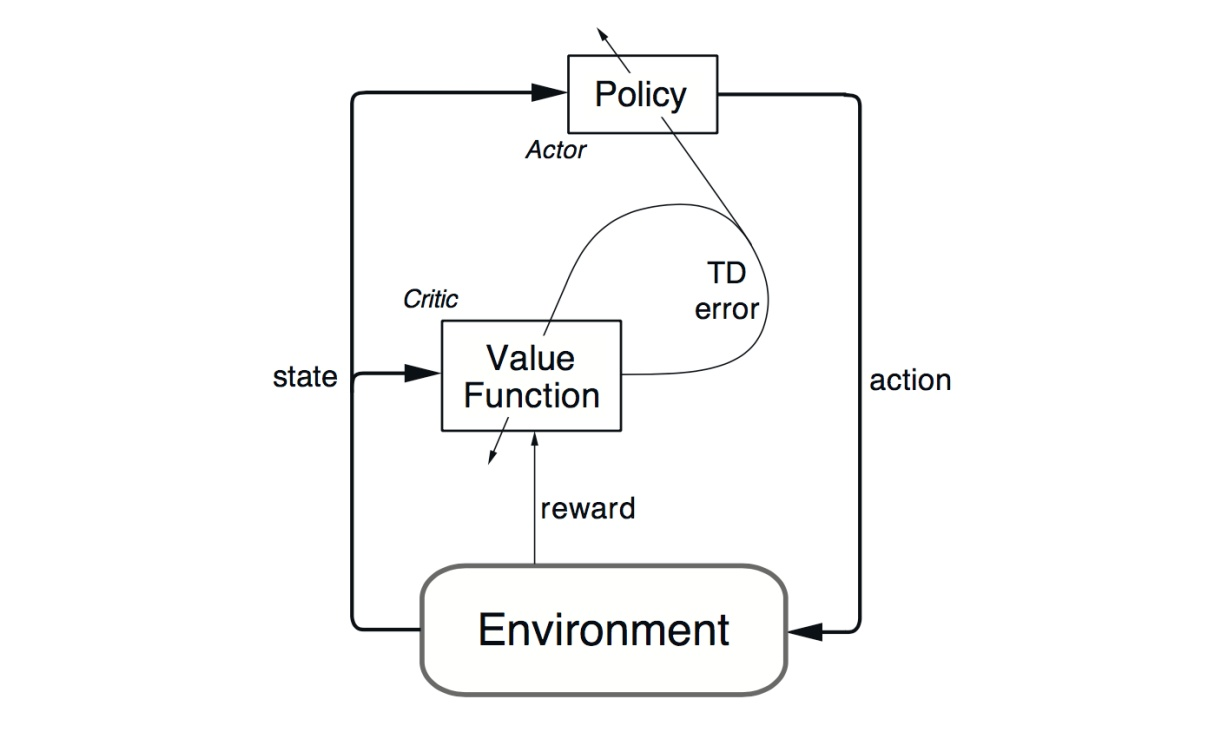
Policy Gradient methods have convergence problem which is addressed by the natural policy gradient. For this reason, PPO formalizes the constraint as a penalty in the objective function instead of imposing a hard constraint.
Although Deep Q Learning uses a deep neural network for calculating the Q values, the decisions were made by a simple Value function and it is almost impossible for DQN to solve the complicated problems.
Proximal Policy Optimization performs better than DQN, but a policy gradient method will always have to confront a slow convergence.
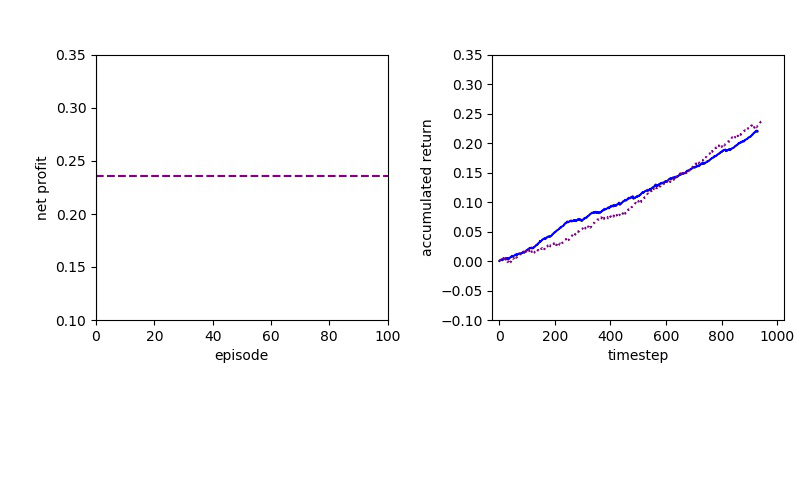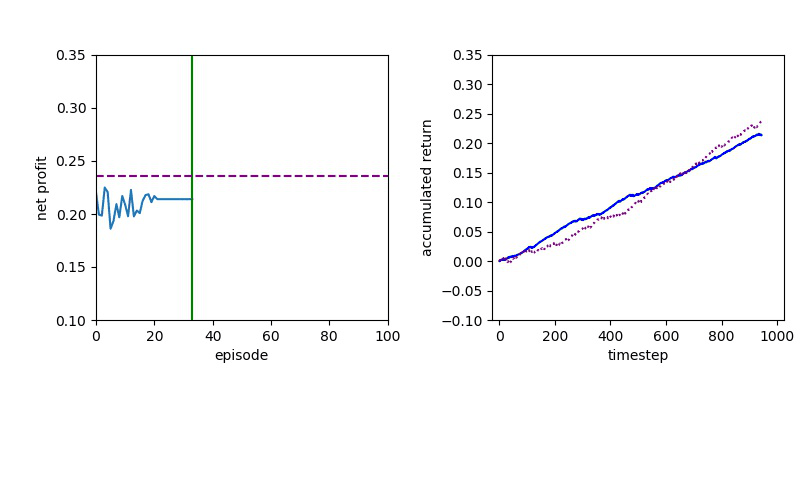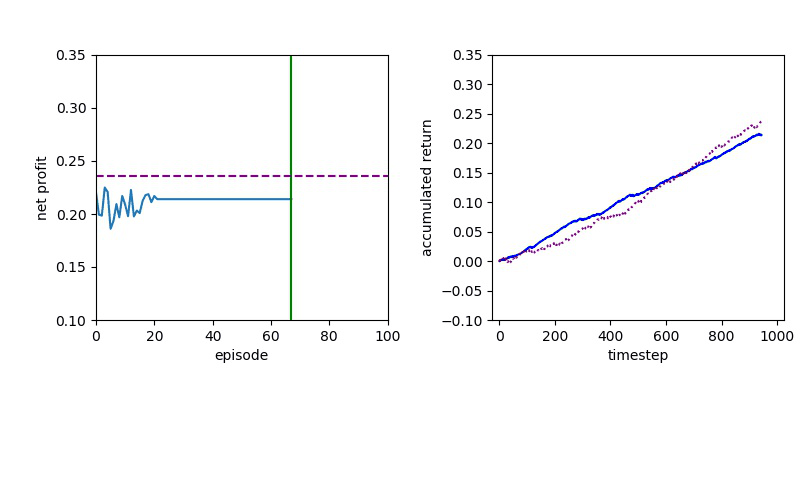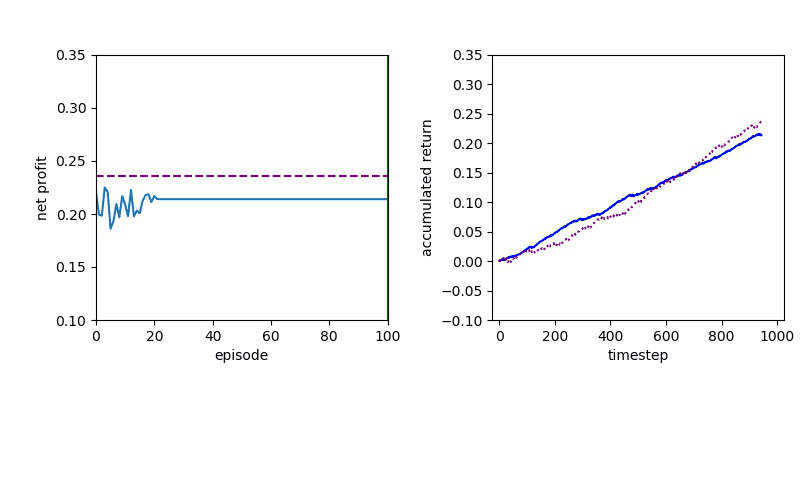
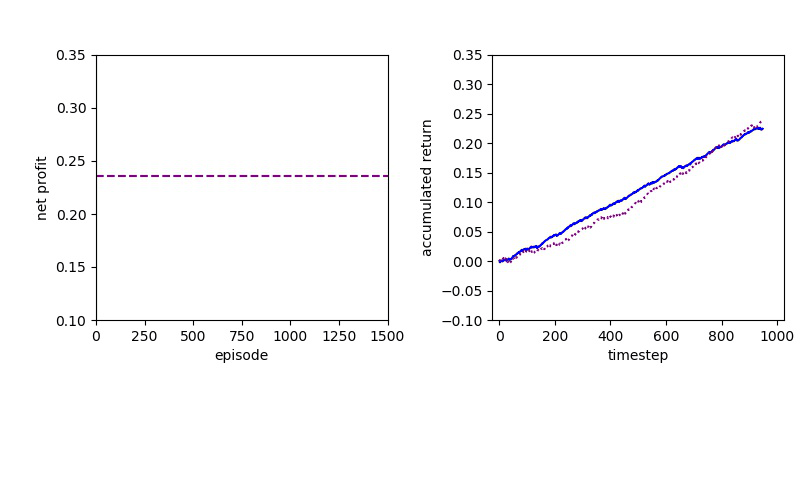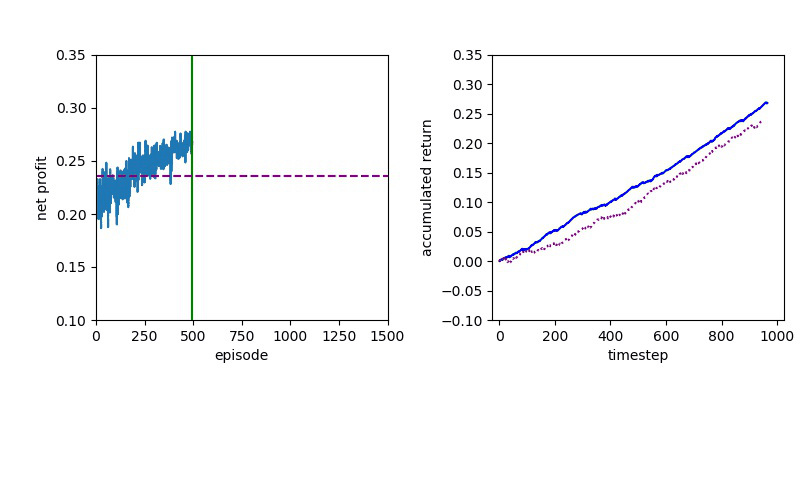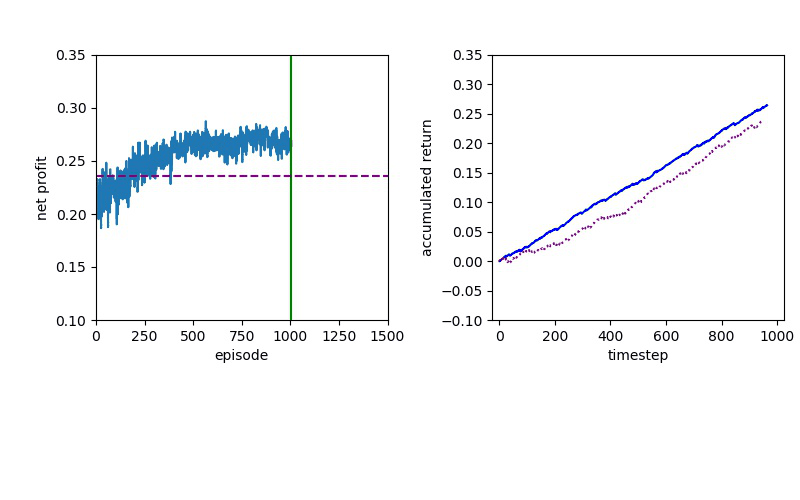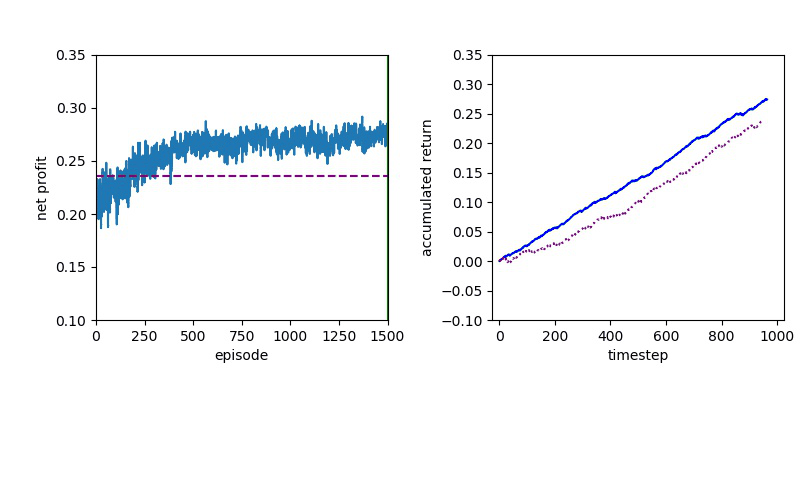
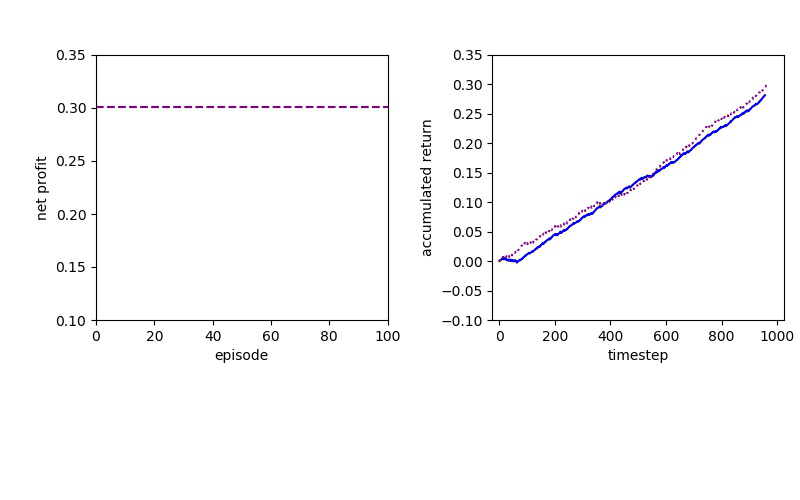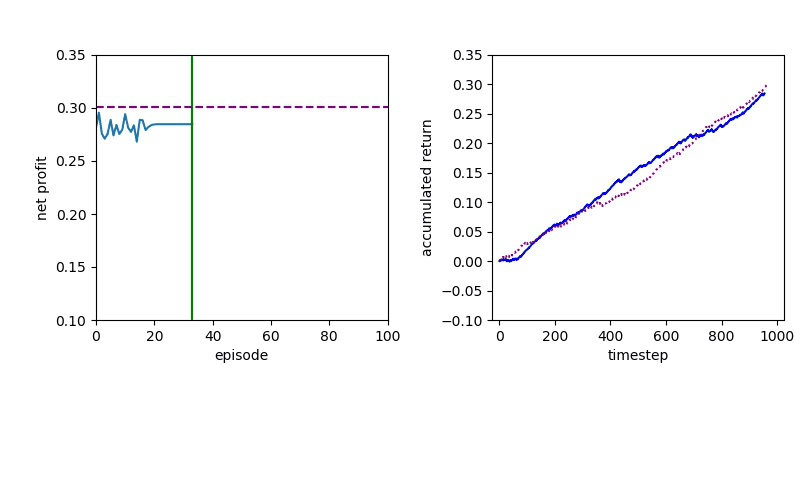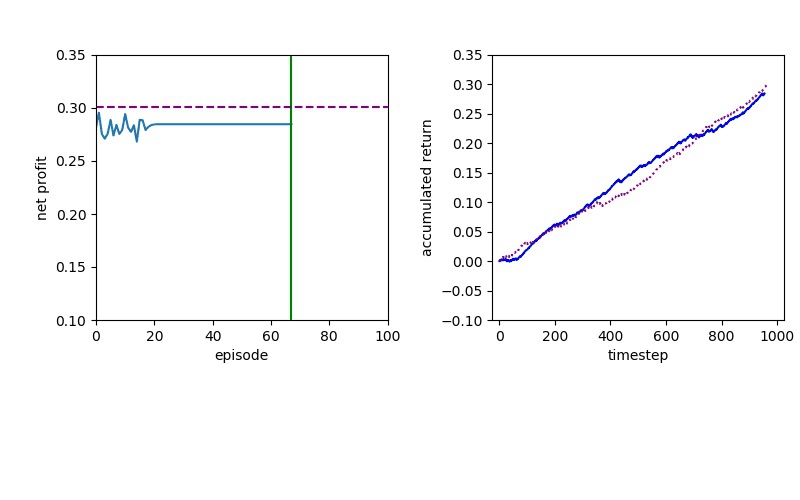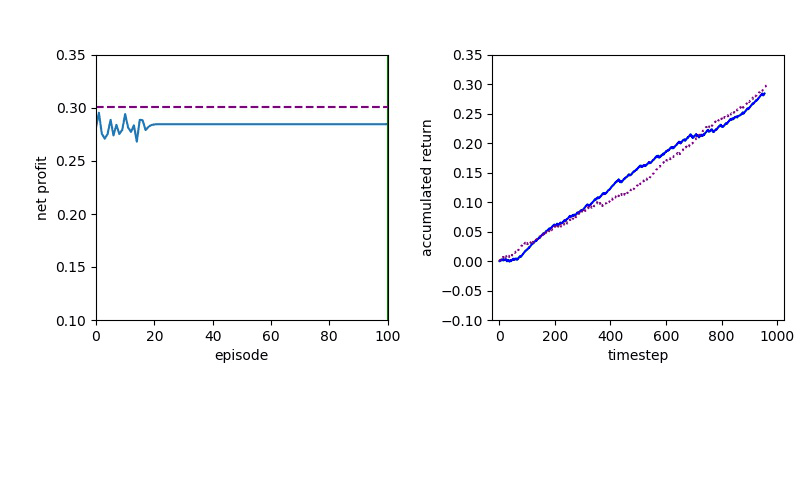
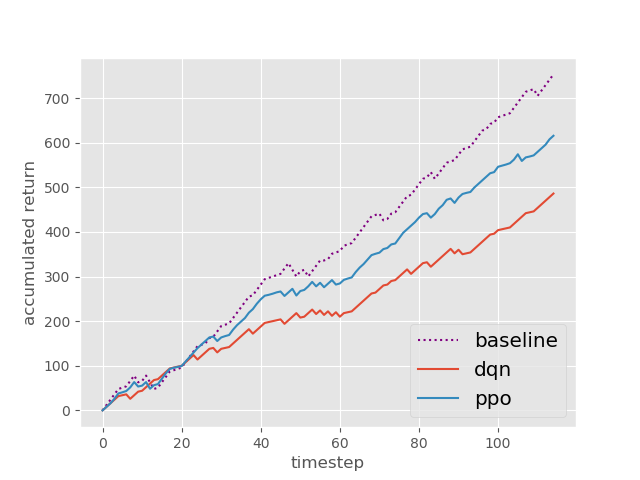
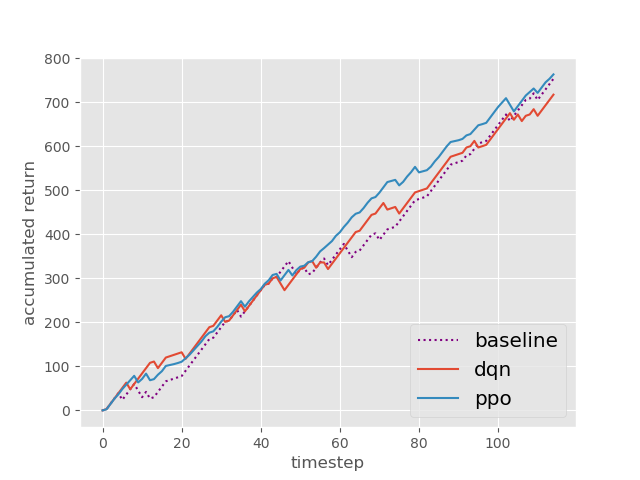
Now I will show you the results of trading with the models over the next month...
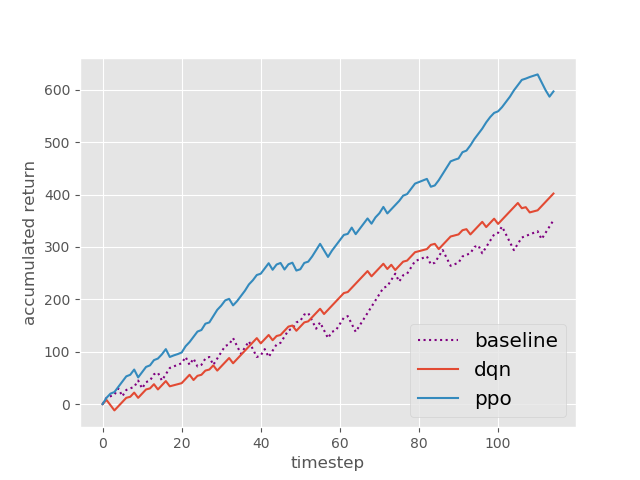
| Net Profit | Profit Factor | Max Drawdown | |
| Baseline | 351 | 1.62 | -14.53% |
| DQN | 402 | 2.32 | -5.97% |
| PPO | 597 | 2.85 | -7.62% |